You don’t have a logistics problem. You have a trade-off problem.
Most networks try to solve trade-offs through local heroics: saving a customer order, protecting a cutoff, keeping a hub “green.” The catch is that every local win can create an enterprise loss, because the network pays the bill somewhere else: premium freight, split shipments, emergency inventory moves, overtime volatility, or downstream congestion.
This is the orchestration failure pattern: local optimization driving global inefficiencies. And it explains why visibility alone doesn’t change outcomes.
In un-orchestrated networks, 15–25% of operational spend becomes reactive recovery costs that wouldn’t exist at this scale if the network could make trade-offs explicitly and two steps ahead.
The prize: What orchestration prevents
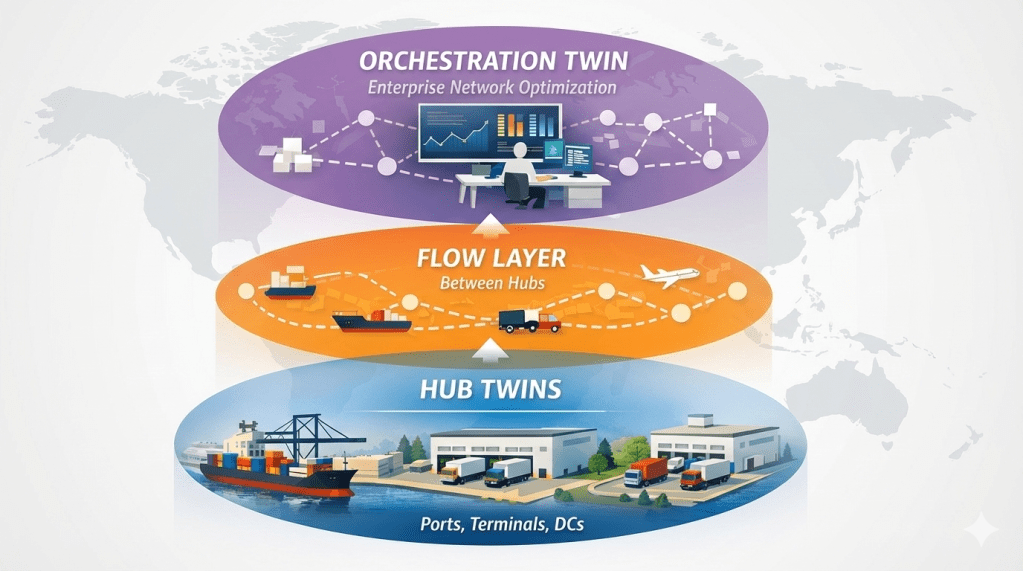
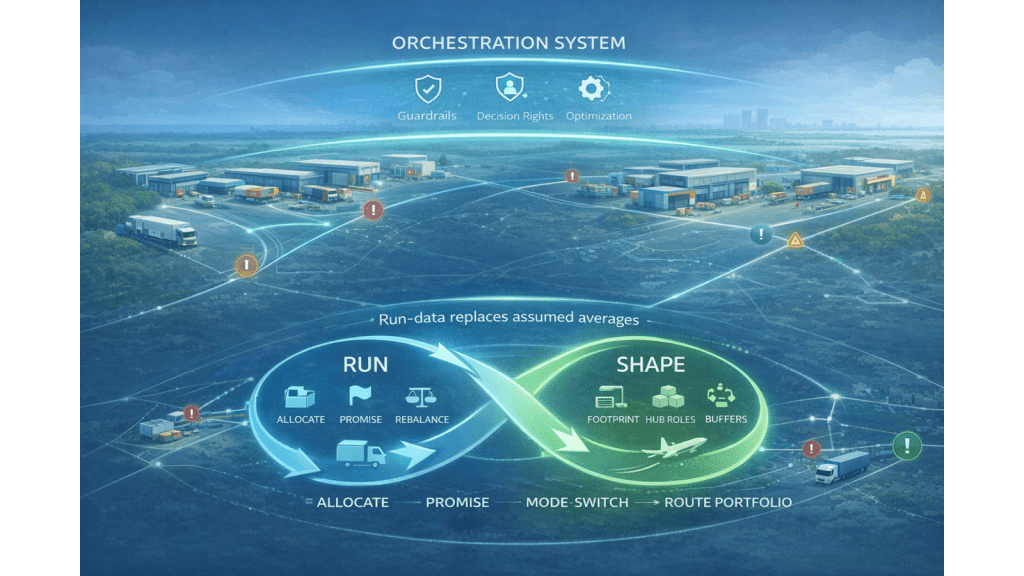
The Orchestration System is the enterprise layer that continuously optimizes network decisions, allocation, promises, inventory moves, and mode/route choices, within explicit guardrails, and pushes decisions into execution.
It prevents three things executives care about:
1) Margin shocks disguised as “service saves.”
Orchestration stops premium moves and emergency measures from becoming the default recovery mechanism. It makes expediting deliberate, not habitual.
2) Organizational arbitrage replacing decision-making.
In many networks, enterprise trade-offs happen through calls, chats, and escalation threads. The loudest voice or most urgent customer wins. That’s not a decision system—it’s organizational arbitrage. Orchestration makes trade-offs explicit, repeatable, and governable.
3) A network designed on assumed averages.
Without orchestration, network design is often updated using assumed stability. Orchestration closes the loop between real variability and structural redesign—so the network gets better over time, not just busier.
A short recap
Parts 1–3 in this series showed how to generate decision-grade commitments from hubs, ports, and warehouses. Part 4 shows what becomes possible when those commitments feed enterprise decisions.
Orchestration only works if local twins produce credible commitments, otherwise you automate bad assumptions.
Control tower vs Orchestration System
A control tower answers: What is happening? Where are we off plan?
An orchestration system answers: What should we do now, across the whole network, and what trade-offs are we willing to make?
That shift matters because the real challenge isn’t finding exceptions. It’s choosing the best response for the network, not for one function, site, or KPI.
Three orchestration examples
- Promise vs Expedite
A key customer order is at risk because a hub is congested and the planned linehaul will miss cutoff. A control tower flags red; the typical response is premium transport because saving service is culturally rewarded.
The Orchestration System forces the right question: Is expediting value-creating—or just habit? High-criticality/high-margin orders may get premium moves. Others are re-promised early to protect the week’s flow. The win isn’t “never expedite.” It’s expedite deliberately.
- Flow-path Decisions
Inbound arrives at a DC and put-away looks sensible: it looks tidy and it “uses available space and capacity.” But downstream demand is building elsewhere, and replenishment lead times mean tomorrow you’ll ship partials or split loads, triggering premium moves.
Orchestration treats this as a network decision, not a site preference. It may cross-dock a portion immediately to protect demand, put away the rest, and adjust allocation logic for 48 hours. This prevents transport from paying for warehouse decisions later.
This is where cost-to-serve stops being a spreadsheet exercise and becomes daily behavior.
- Mode Switching
A disruption hits and the instinct is to buy speed: air, premium road, diversions. Sometimes it’s right. Often it protects today by creating tomorrow’s congestion and cost.
The Orchestration System evaluates mode switching through a network lens: will it protect a critical customer or consume scarce capacity and trigger more premium moves tomorrow? It may switch mode for a narrow segment, reroute some flows, and re-promise early elsewhere.
What it takes: guardrails + decision rights
Orchestration is not an algorithm issue first. It’s a governance and decision-rights topic, supported by technology.
Three requirements separate orchestration from spreadsheets and escalations:
1) Decision-grade commitments from the operational twins.
The elements discussed in articles 1–3 deliver the inputs: credible capacity, timing, and constraint signals that can be trusted at enterprise level.
2) Guardrails that make trade-offs governable.
Not rigid policies, boundaries that stop you from “winning today by breaking the network,” such as margin floors, service-tier rules, capacity protection for critical nodes, and risk/compliance constraints.
3) Clear decision rights.
Who can change appointments, promises, allocations, and modes—when constraints change? Without decision rights, orchestration collapses back into escalation threads.
The final concept: the Run >> Shape flywheel
Orchestration is not only how you run the network. It’s how you continuously redesign it.
- Run (today/this week): allocate, promise, re-balance inventory, mode-switch, reroute, using real commitments from hubs and flows.
- Shape (this quarter/this year): redesign hub roles, buffers, footprint, and route portfolio using the variability the twins actually observed.
This is the ultimate win: run-data replaces assumed averages. Network design stops being an annual spreadsheet ritual and becomes a learning system, the network improves structurally, not just operationally.
Where AI fits
AI won’t fix unclear decision rights or bad guardrails. It will just automate them faster. AI won’t magically solve enterprise trade-offs; you still need to define what’s worth optimizing for.
But when the foundations are right, AI matters in three concrete ways:
- Sense earlier: better prediction of variability and knock-on effects, so decisions happen before chaos locks in.
- Decide faster: AI-assisted optimization and agentic approaches can propose and test actions continuously, compressing the cycle from exception to action.
- Learn over time: the system improves decision rules based on what worked in reality, turning orchestration into a learning engine, not just a faster planner.
AI is an accelerant for orchestration, not a substitute for governance.
How to start
Start with one enterprise decision and make it measurable: promise vs expedite, flow-path choices, or mode switching. Define guardrails first. Use commitments from Parts 1–3 as inputs. Run a closed loop (decide → execute → learn). Expand scope only when trust is earned.
What questions to ask
- What share of our operational spend is reactive recovery vs planned execution?
- Who has explicit authority to make enterprise trade-offs—and what guardrails constrain them?
- Are we measuring hubs and flows on local efficiency or network contribution?
- When we “save” a customer order, do we know what it cost the network?
- Is our network design based on what actually happens—or what we assumed would happen?
Closing
The network you have today is the result of a thousand local optimizations. The network you need tomorrow is the result of designing trade-offs explicitly—and learning from what actually happens, not what you assumed. That’s what the Orchestration System delivers and a network that becomes structurally better over time.